
How to Sync Google Forms Responses to Google Calendar Using GAS
sanane SANANEBLOG

最近毎日行うブラウザ上の操作があり、単純作業であったためどうにか自動化できないか、と悩んでいました。定期実行させるためにクラウド上や自宅にサーバーをわざわざ立てるのは費用がかさむ。。
ということでサーバーレスであるAWS LambdaとSeleniumを使用してブラウザ操作を定期的に実行するよう自動化してみました。
ネット上にはたくさん情報が転がっておりそれらを参考にさせていただいたのですが、どうも私の場合はうまく行かず躓いた部分が多々あり、コードなど自分用にカスタマイズしてようやく動作しました。備忘録も兼ねて成功した手順を記載します。(2023年動作確認済み)
【AWS Lambda】Pythonのseleniumで定期実行する
大まかな手順はこちらのサイトを参考にさせていただきました。以降の手順で詳細な箇所が不明な場合はこちらをご参考に進めてください。
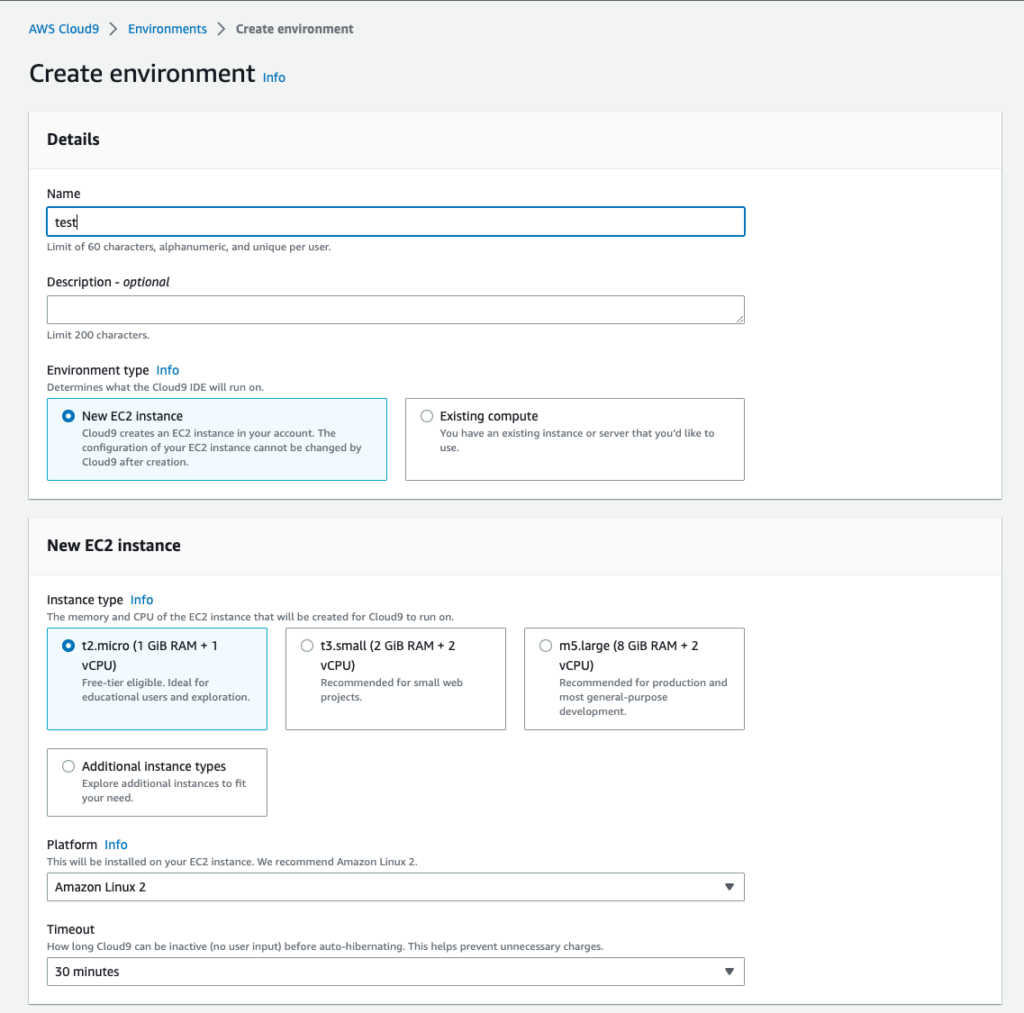
リージョンは東京、[AWS Cloud9]>[Environments]>[Create environment]から環境を作成します。環境名は任意のもの、ほかはすべてデフォルトで作成します。
作成後環境下部のターミナルから下記のコマンドを実行します。
他サイトとは以下が異なります。
・Seleniumを配下ではなくフォルダ配下にインストールしていること
・Headless-chromiumとChromedriverのバージョン
#pythonフォルダを作成しSeleniumをインストールする
pip3 install selenium==3.141.0 -t ./python
#作成されたpythonフォルダをzip化する
zip -r python python
#headlessフォルダ配下を作成して移動
mkdir -p headless/python/bin
cd headless/python/bin
#headless-choromiumv1.0.0-55をインストール
curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
#headless-chromium.zipを展開する
unzip -o headless-chromium.zip -d .
#headless-chromium.zipを削除する
rm headless-chromium.zip
#ChromeDriver2.4.3をインストール
curl -SL https://chromedriver.storage.googleapis.com/2.43/chromedriver_linux64.zip > chromedriver.zip
#chromedriver.zipを展開する
unzip -o chromedriver.zip -d .
#chromedriver.zipを削除する
rm chromedriver.zip
#作業フォルダに移動
cd ./environment
#headlessフォルダをzip化する
zip -r headless headlessコマンド実行後のフォルダ構造は以下のようになっています。
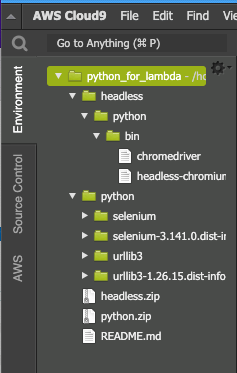
作成された[headless.zip]とを右クリックからローカルにダウンロードし、[AWS Lambda]>[レイヤー]>[レイヤーの作成]からアップロードします。
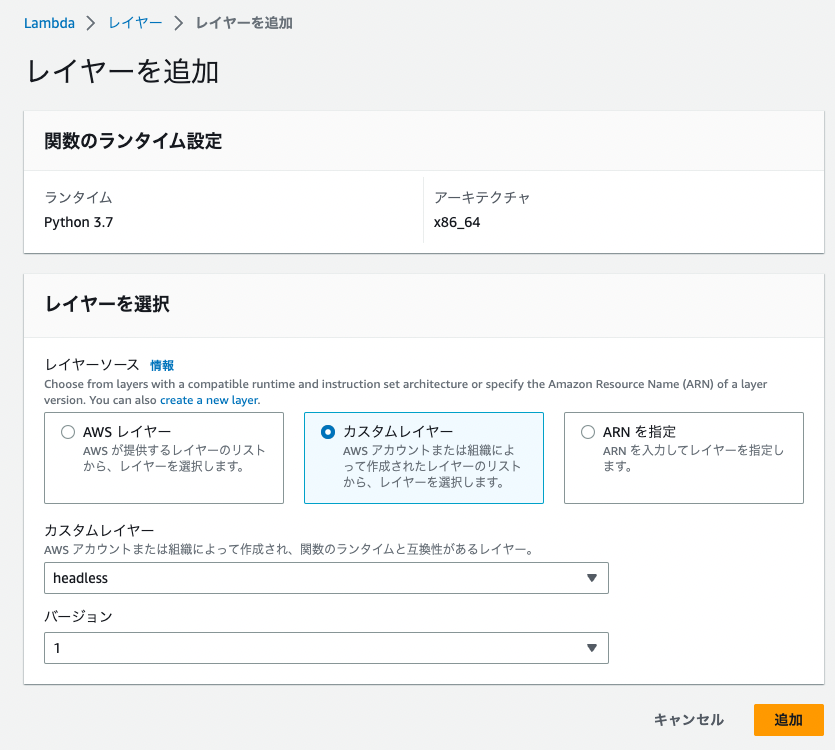
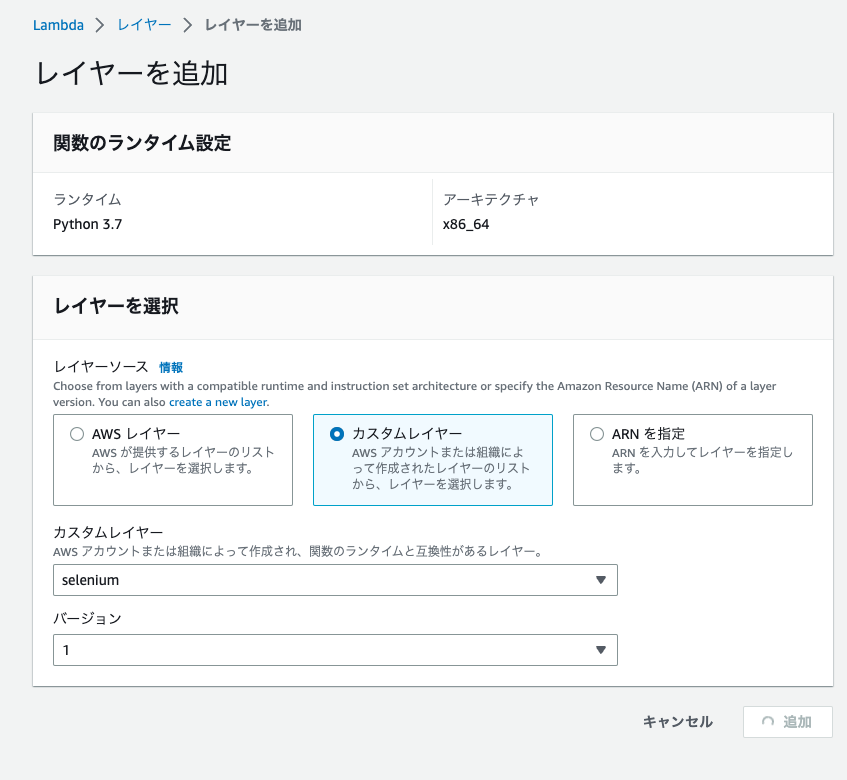
をアップロードしたレイヤーの名前は[selenium]、[headless.zip]をアップロードしたレイヤーの名前は[headless]として2つ作成してください。ランタイムはとなります。
画像は[selenium]の場合のレイヤー作成画面となります。
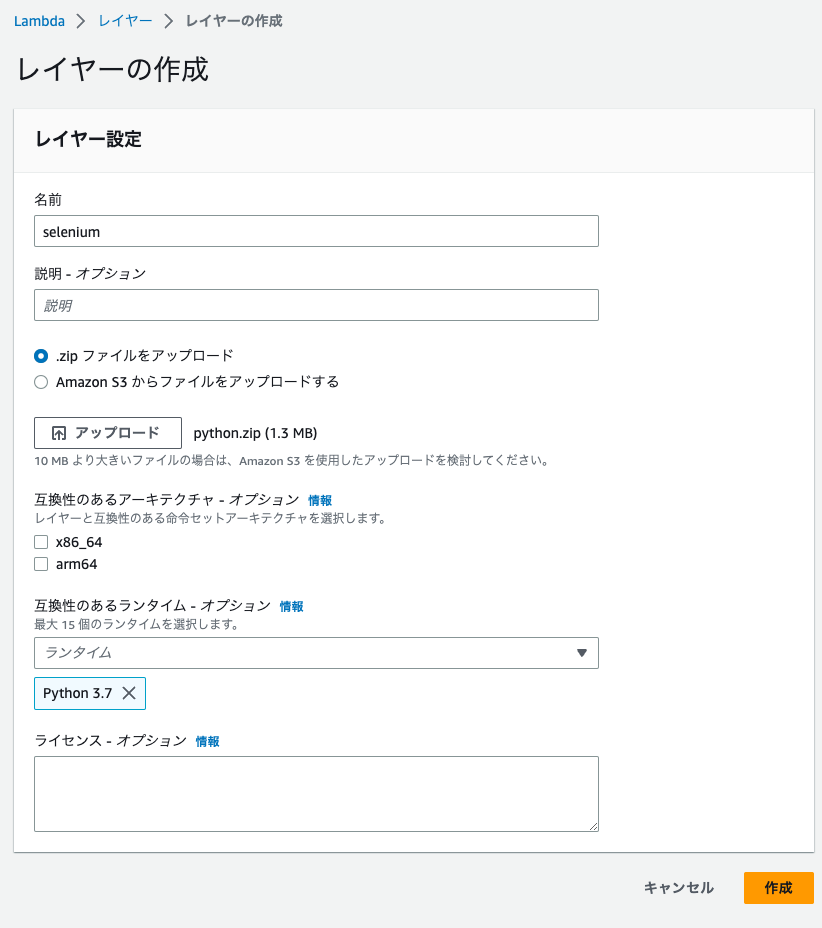
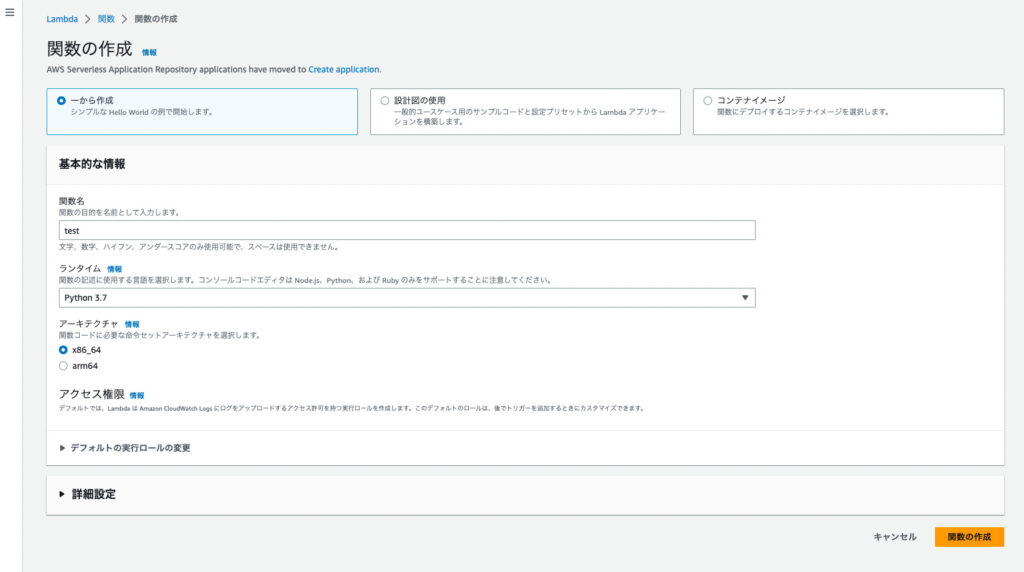
レイヤーを2つ作成したら、[Lambda]>[関数]>[関数の作成]から関数を作成します。
[関数名]は任意の関数名、[ランタイム]はを選択し残りはデフォルトで[関数の作成]をクリックします。
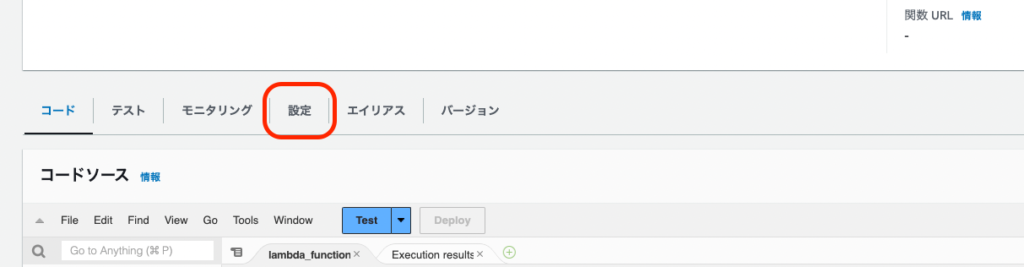
関数作成後、[Lambda]>[関数]>[任意の関数名]の画面で下までスクロールするとレイヤーの追加画面があります。
[レイヤーを追加]をクリックして先程作成したレイヤー[headless][selenium]をそれぞれ追加します。
追加後、関数の設定をクリックします。
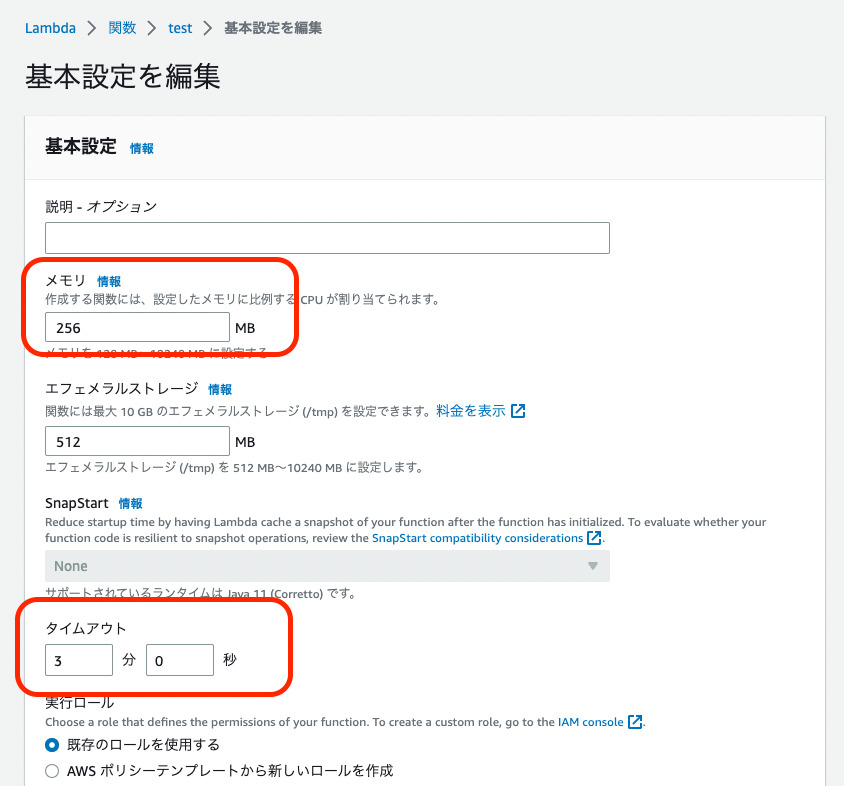
メモリを[256MB]、タイムアウトを[3分]に設定して保存をクリックします。
[コードソース]画面で[Lambda_function]に以下のテストコードを記入します。
from selenium import webdriver
def lambda_handler(event, context):
url = "https://yahoo.co.jp/"
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("start-maximized")
options.add_argument("disable-infobars")
options.add_argument("--disable-extensions")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1180x996")
options.add_argument("--no-sandbox")
options.add_argument("--single-process")
options.binary_location = "/opt/headless/python/bin/headless-chromium"
#ブラウザの定義
browser = webdriver.Chrome(
"/opt/headless/python/bin/chromedriver",
options=options
)
#以下自動化処理
browser.get(url)
title = browser.title
browser.quit()
return titleコードを記入したら[Deploy]をクリックし、正常に更新されたら[Test]をクリックして任意のイベント名の記入、その後もう一度[Test]をクリックして表示される実行結果にエラーが表示されていなければ成功となります。
以上がAWS LambdaとSeleniumを使用したブラウザ自動化実行方法となります。
サンプルコード内のオプションも少しカスタマイズしているので、もしほかのサイトのやり方が上手く行かなかった場合はこちらを試していただければと思います。




